AI : MLOps
Ml Ops 개론
문제 정의
EDA
Feature engineering
train
predict
(deploy) : 서비스 배포
- 모델 결과값이 이상하면
- 원인 파악, 인풋 이상치 확인
- 모델 성능이 이상
- 정형 데이터는 알 수도 있지만 비정형은? -> 모델이 좋은지 확인
- 새로운 모델이 더 안 좋다면?
- 과거의 모델을 쓰기 위한 작업 필요.
ML Ops 란?
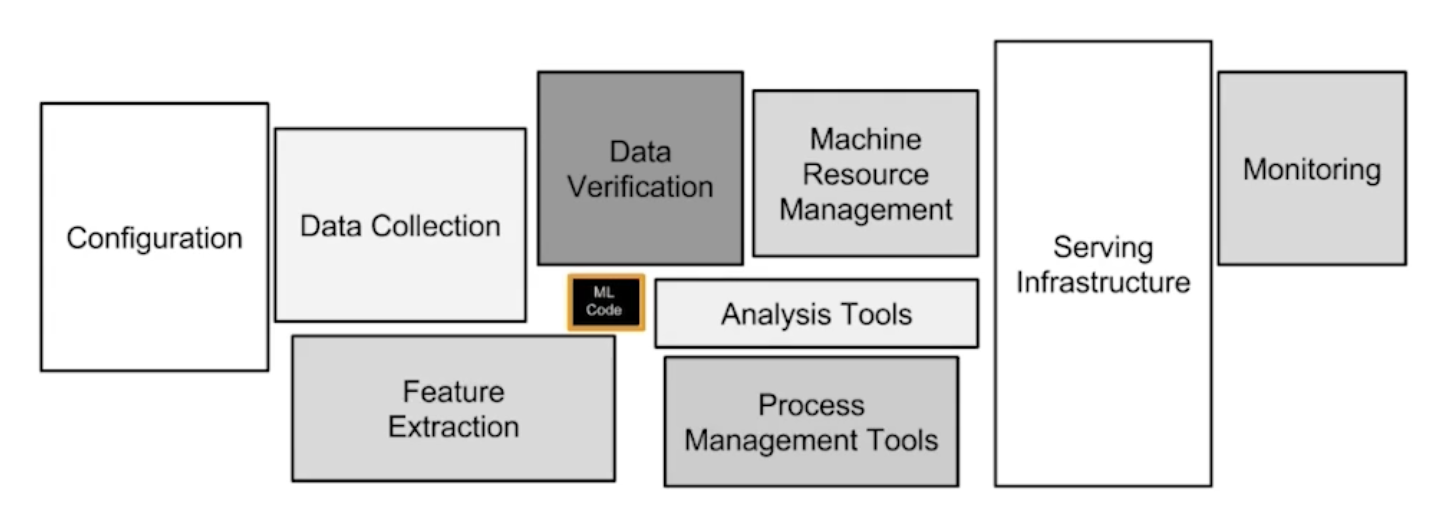
머신러닝 뿐만 아니라 데이터 엔지니어링, 클라우드, 인프라 등을 만들고 자동으로 운영되도록 만드는 일.
https://zzsza.github.io/data/2018/01/28/hidden-technical-debt-in-maching-learning-systems/
-> 아이디어 부터 production 까지
라이브러리에 집중하기 보다는 왜, 어떻게 쓰는지에 집중하여 학습하자( 너무 많음)
MLOps : 어떤 문제를 해결하고 싶고, 그 문제를 어떤 방식으로 해결할지 공부
MLOps Component
Server (인프라)
트래픽/ CPU, 메모리/ 스케일 업,아웃 가능 / 자체 서버 구축 or 클라우드
Serving
- Batch serving : 데이터 처리 묶어서 한번에
- Online serving : 한번에 하나 씩 실시간 전달.
Experiment, Model management
어떤 조합이 좋은지 기록해보면서 최고의 조합을 찾음.
모델 생성일, 모델 성능, 모델 메타 정보 등을 기록해 둘 수 있음.
공통의 코드를 작성하여 알아서 작성될 수 있도록 함.
- 대표적으로 mlflow 가 있다. autologging 기능이 있어서 알아서 실험이 기록된다.
팀프로젝트 공용 mlflow 서버를 만들면 누구꺼가 더 좋은지 비교도 가능.
Feature Store
: 미리 프리셋을 만들어 놓자.
-> 데이터 전처리 시간을 줄일 수 있다. (단 tabular 데이터에서 많이 사용됨)
ex) FEAST
Data validation
: feature의 분포 차이 확인 (재료 확인)
Data drift, model drift, Concept drift ex) TFDV, AWS Deequ
Continuous Training
: 새로운 데이터가 도착한 경우 새롭게 모델 retrain
1) 새로운 데이터 2) 일정 기간마다 3) metric 기반 score 감소 4) 요청시
Monitoring
로깅 잘하자
AutoML
데이터만 주면 알아서 모델을 만드는 경우
ex) Microsoft nni
Further Question
- MLOps가 필요한 이유 이해하기
패턴이 있는, 복잡한 문제를 풀기 위한 ML을 효과적으로 사용하기 위하여
인프라, 데이터 처리, 서빙, 모니터링, 로깅 등을 자동으로 이뤄지게 하여 최고의 효율을 이끌어내기 위해서
- MLOps의 각 Component에 대해 이해하기(왜 이런 Component가 생겼는가?)
- 1) Serving
-
데이터를 받아와서 저장할 장소가 있어야 한다. 그곳이 인프라 이고, 모델을 통해 이를 분석하여 결과물을 제공하는 것을 Serving이라 한다. Batch Serving : 한번에 많은 양을 일정 주기로 Online Serving : 실시간, 하나씩
2) Experiment, model management
:실험을 통해 어떤 모델이 최상의 결과를 내는지 알아낸다. 이 과정에서 실험 결과들을 자동으로 logging 할 수 있는 방법이 사용되면 베스트. 이를 사용하면 다른 사람들과 협업 하면서도 어떤 모델이 가장 베스트인지도 알 수 있다.
ex) mlflow
3) Feature Store
이미 만들어진거 저장해서 바로바로 사용할 수 있게
ex) Feast, Hopsworks
- 4) Data Validation
-
데이터가 얼마나 달라졌는지 알아야한다. 이를 활용하여 모델을 데이터에 맞춰 재학습하여 성능을 유지시키는 model drift를 하기도 한다. 이는 continuous training으로 연결되어 지속가능한 모델이 되는 듯.
- 5) Monitoring
-
로깅 잘해서 데이터 저장 잘 하자
6) AutoML
모델 알아서 만들거나 미친 기술력
- MLOps 관련된 자료, 논문 읽어보며 강의 내용 외에 어떤 부분이 있는지 파악해보기
Hidden Technical Debt in Machine Learning Systems
https://zzsza.github.io/data/2018/01/28/hidden-technical-debt-in-maching-learning-systems/
technical dept : 실행속도와 엔지니어링 품질 사이의 딜레마
- MLOps Component 중 내가 매력적으로 생각하는 TOP3을 정해보고 왜 그렇게 생각했는지 작성해보기
1) monitoring : 자동으로 결과들을 저장하고 성능을 평가하기 때문에 모델 성능에 중요한 역할을 하지 않을 까 싶다. 이를 통해 모델을 개선할 시점을 잡고 방향성을 잡을 수 있을 것 같다.
2) data validation: 그런 점에서 데이터가 얼마나 달라졌는지 보는 것도 중요할 거 같다.
3) AutoMl : 개쩌는 기술력이지만 막상 써보면 불편할거 같은 이 기술을 언젠가 한번 편하게 써보고 싶다.
댓글남기기