11/14 DKT 첫 날 가즈아
하루시작
2번째 대회 - DKT 가 시작하는 날이다
기본 강의들을 쭉 들어보면서 어떤식으로 진행되는지 살펴볼 예정이다.
오늘 하기로한 크로스핏은 당일 예약이 되지않아 화요일에 할 듯하다.
멘토링
이하경 멘토님 : 무려 meta에 다니신다고 한다!
이력서 내용은 비슷할지라도 열심히 한사람들은 어떤걸 어떻게 했는지 기술하면 다르게 보일 수 있다.
주제
- 라이브코테 세션
- 취업 준비
- system design
- data science 관련 스타트업, 기업들
- MLop에 관하여
- 깃 협업
3기 추천시스템 프로젝트
의외로 음악 추천이 없다?
- 데이터가 있어야 하니까 추천 문제들이 겹치게 되는 경향이 있는거 같다.
- 공중, 시중 데이터/ 크롤링 /
- 개발은 FastAPI로 주로함
-
배포는 주로 GCP, platform 은 주로 Web
- 추천은 nlp나 cv 볼 수 밖에 없어서 같이 공부할 수 있어서 좋은거 같다.
서비스, 데이터 pipe line 를 end to end 로 그려보기 (+ CI/CD까지 해볼 수 있을까?)
시작점
- 내가 관심있는 주제
-> 크롤링
- 준비된 데이터셋
a.추천 데이터 모음 사이트
https://cseweb.ucsd.edu//~jmcauley/datasets.html
b. 챌린지 데이터셋
카카오아레나, 캐글
파이널 프로젝트를 끝내고 Recsyschallenge에 기재해볼 워크샵 페이퍼를 적어보는 것도 좋은 아이디어이다.
ex) 비슷한 옷을 추천해주는 work
1강 DKT
: 딥러닝을 이용해서 하는 지식 상태 추적
-> 문제추천, 학업도 파악 등으로 활용
-> 대회에서는 주어진 문제를 맞췄는지 틀렸는지 예측(binary)하는데 집중한다.
데이터가 부족하면 overfitting이 일어남
-> Regularization, drop-out, batch-norm, data augmentation, 데이터 추가
Metric (평가지표)
- AUC / ACC
Confusion Matrix
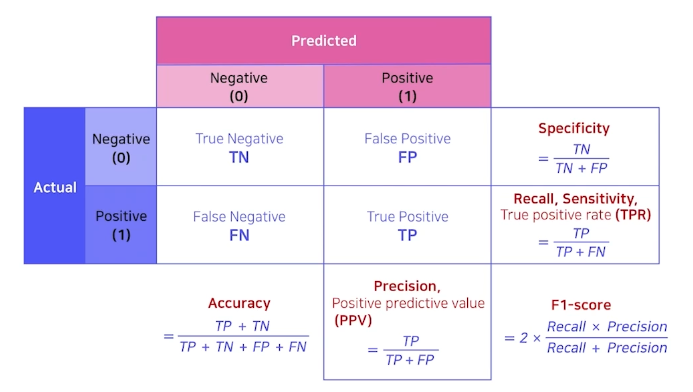
AUC : Area Under the roc Curve
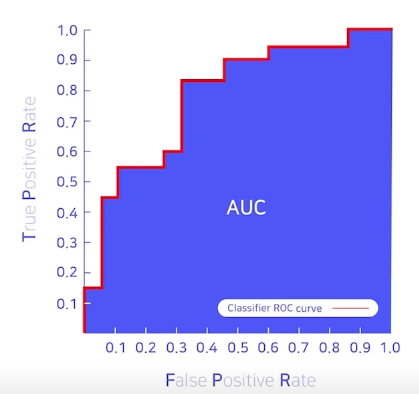
맞으면 위로, 틀리면 오른쪽으로 이동함.
특징 2가지
- 척도 불변.
- 분류 임계값 불변
단점 2가지
- 척도 불변이 항상 이상적이진 않다. (잘 보정된 확률 결과가 필요할 경우)
- 분류 임계값 불변도 이상적이진 않다. (FP, FN중 하나를 우선시 하고 싶을 경우)
DKT History
최근에는 transformer 사용한 SAKT, GNN 사용한 GKT 가 있다
추가적으로 SAINT, SAINT+ 도 중요한 발전이다.
아무래도 Sequence Data를 다루니까 NLP에 연관이 많다.
- RNN -> 장문장에서 학습이 어려움
- LSTM
- Seq2Seq -> 인코더 디코더 방식 적용 (CV : context vector) -> 문장이 길어졌을 때 문제 발생
- Attention -> 학습속도가 좀 느리다 (seq 정보 때문에)
- Transformer -> 병렬처리를 위해 seq를 끊고, 어순 정보는 Positional encoding(후에는 Embedding) 으로 해결
2강 DKT EDA
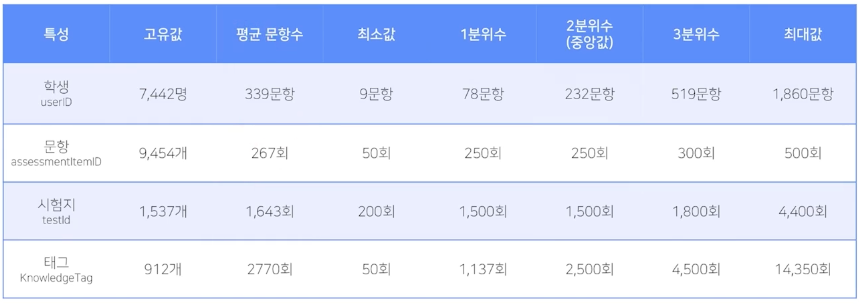
- 데이터의 형태 DKT 는 하나의 행을 “Interaction” 이라고 부름
6개의 Feature
데이터 크기 : 2526700 x 6
-
userID : (7441 명)
-
assementItemId : 시험 문항 (9454 개) 10자리로 구성

- testId : 시험지 (1537개) 10자리로구성


앞 3 : 대분류 feature 가 3 : 시험지 번호 뒤 3 : 시험지 내 문항 번호
-
answerCode : 맞았는지(1) 틀렸는지(0) (65.45%가 정답을 맞춤)
-
Timestamp : 문제를 풀기 시작한 시간
-
KnowledgeTag : 어느 영역의 문제인지 (912개)
기술 통계량
데이터가 주어지면 분석하자 슈발
- 사용자 분석
사용자당 : 평균 339문항, 최소9문항, 최대 1860 문항
정답률 : 평균 62.8% , 최소 0%, 최대 100%, 중앙값 65.1%
- 문항/시험지 별 분석
문항 : 평균 65.4 , 최소 4, 최대 99.67
시험지 : 평균 62.8 , 최소 0, 최대 100, 중앙값 65.1
특성별 빈도 종합 분석
정답률 분석
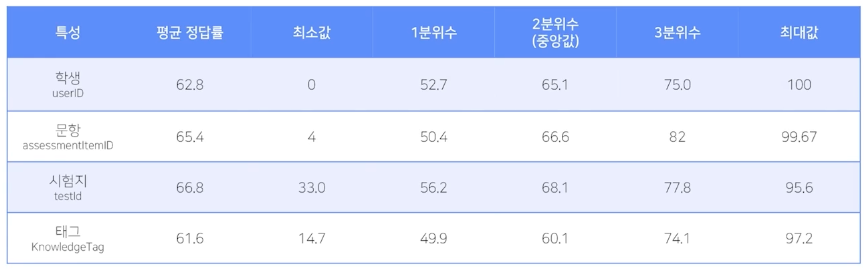
일반적인 EDA
- 문제를 많이 풀면 더 잘 맞출까? -> 문항수와 학생의 정답률 : 0.171 상관계수
- 더 많이 노출된 태그가 정답률 더 높을까?-> 분포에 차이나 난다!
- 문항을 풀 수록 실력이 증가하는가?
- 문항을 푸는데 걸린 시간과 정답률 사이의 관계는?
회고
오늘도 집중력이 많이 좋지 않았다. 성연님은 같은 시간안에 baseline 한번 보고 2강까지 본뒤에 EDA 까지 하고 있던거 보니까 아직 나는 갈길이 멀다는 걸 느꼈다.
노션 페이지는 내가 원하는 대로 웬만하게 다 깔끔하게 만들 수 있어서 뿌듯하다.
추천이라 하면 유튜브나 스포티파이 추천을 생각했지만 생각보다 추천의 범위가 더 넓다는 것을 느꼈다. DKT도 그렇고 생각보다 방법론?적인 방식도 추천에 속하는구나 라는 것을 느꼈다.
NLP 강의도 이번주에 같이 들어놓으면 좋을 것 같다는 생각이 들었다.
질문
- fastapi? 이거는 어떻게 배우는지 궁금하다
- multimodal? 이게 대체 무슨 개념인데
- CI/CD
- streamlit 언제 할껀데?
TIL
깔끔한 조 세팅- 노션, 깃헙
데이터 분석
댓글남기기