DL-5 CNN example
네트워크는 깊게 parameter는 작게 성능은 높게 하는 과정들을 보여주마
AlexNet
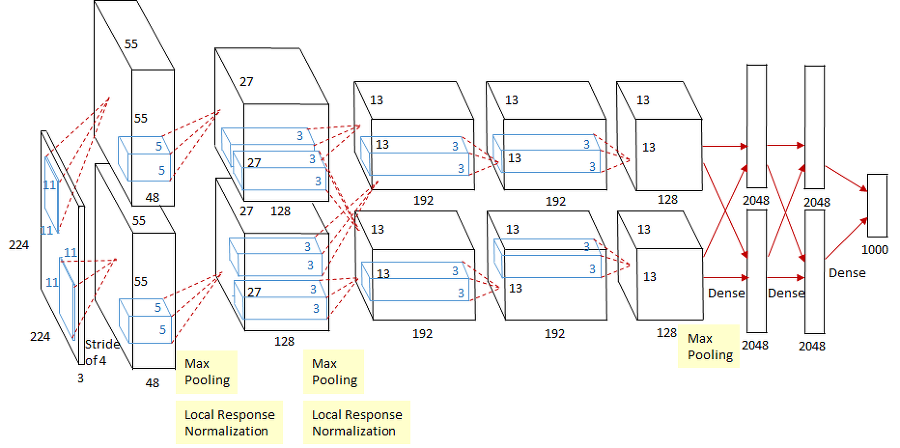
성공 이유
-
ReLU 사용 linear model 들의 성질 보존 vanishing gradient 문제 극복 gradient descent에 적용 쉽 generalization에 좋음
- GPU 사용 (2개)
- LRN, Overlapping pooling (요즘 안씀)
- Data augmentation
- Dropout
VGGNet
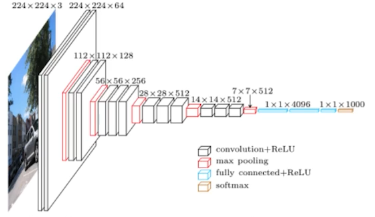
Why 3x3 convolution?
3x3 두개를 사용했을 때 가 5x5 한개 사용했을 때보다 parameter수가 적다
GoogLeNet
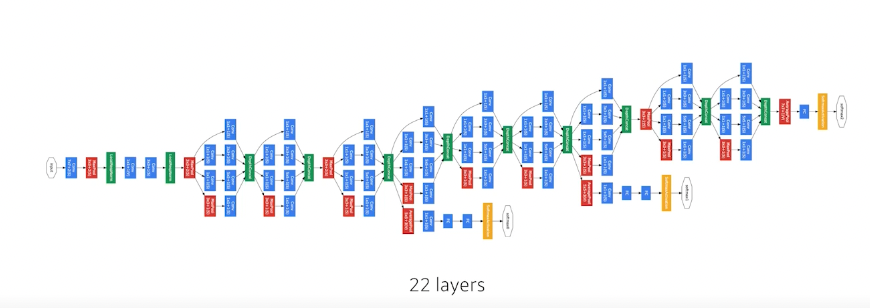
- NiN 구조(Network in Network)
- Inception Block
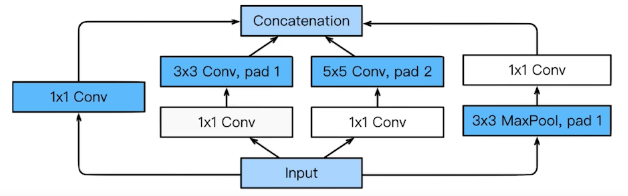 1x1 으로 parameter수가 1/3로 줄음
1x1 으로 parameter수가 1/3로 줄음
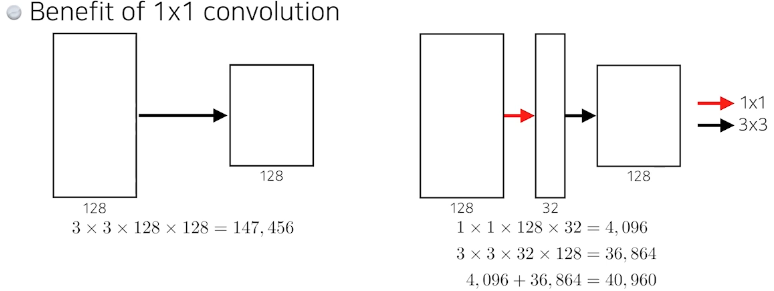
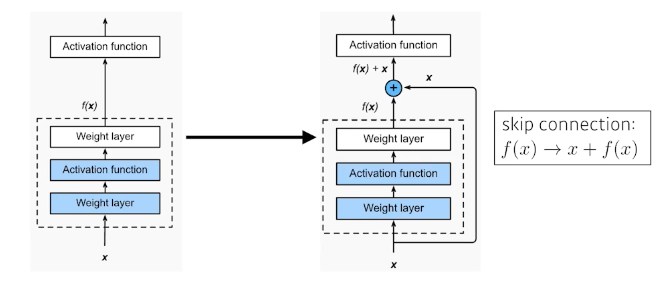
ResNet
이전의 네트워크가 커짐에 따라 학습이 제대로 이뤄지지 않는 문제를 해결하기 위한 방법 제시
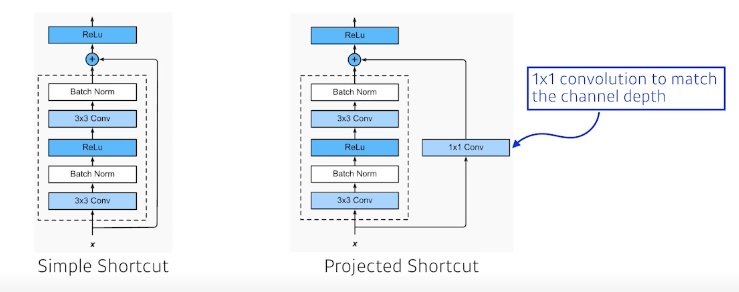
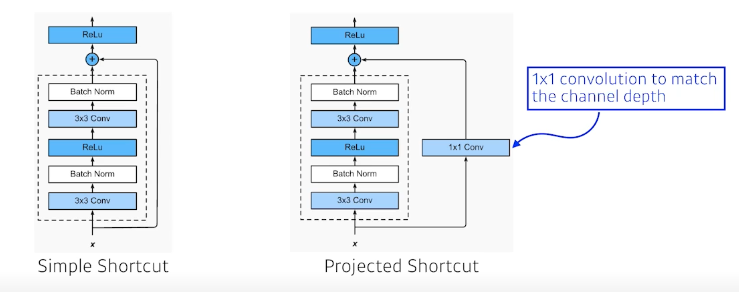
차원을 같게 하기 위해 1x1 convolution 방법도 추가(근데 많이 안씀)
DenseNet
resnet에서 더하면 값이 섞이니까 concat하면 어떨까
 concat은 채널이 점점 커지는 단점이 있다.
concat은 채널이 점점 커지는 단점이 있다.
중간에 채널을 한번씩 줄이는 과정 -> 1x1 conv 사용
댓글남기기