DL-6 Computer Vision Applications
Semantic segmentation
물체 (사람, 차, 동물 등등) 분류
Fully Convolutional Network
마지막에 dense layer (FC layer) 를 없애고 convolution으로 처리함
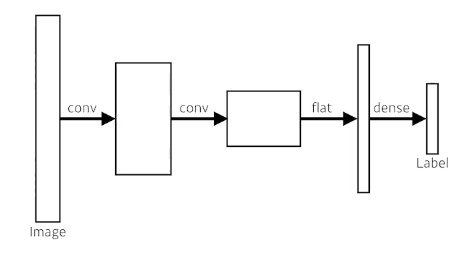
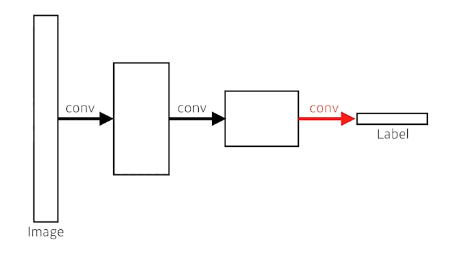 이 과정을 convolutionization 이라함
이 과정을 convolutionization 이라함
이를 통해서 heat map - 고양이 얼굴이 사진중에서 어디 있는지 rough 하게 알 수 있는 기술 이 가능 해짐
Deconvolution (conv transpose)
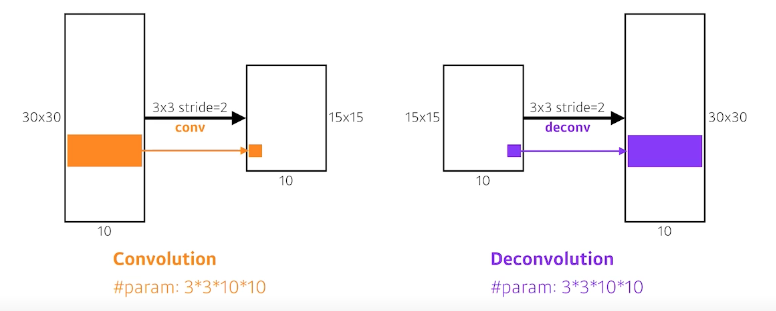
이런식으로 결국 만들어 진것이 FCN
Detection
bounding box를 찾는 task
R-CNN
detection의 가장 간단한 방법 1) 이미지에서 2) bounding box 뽑고 (selective search 이용) 3) region에 대한 feature를 CNN을 통해 얻어내고 4) 분류하자 (linear SVMs 이용)
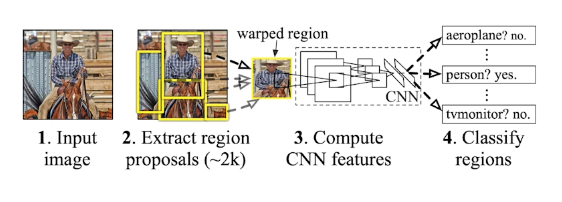
문제점 : bounding box를 2000개 뽑으면 모두 CNN 돌려야 되니까 시간이 오래 걸린다.
SPPNet
CNN을 한번 돌려서 얻어지는 convolution feature map 위에서 (tensor) bounding box를 뜯어오는 개념
Fast R-CNN
sppnet과 비슷 1) 인풋 들어오면 bounding box들을 뽑음 2) convolution feature map 3) 각각의 region에 대해서 fixed lenght feature 뽑음(ROI pooling) 4) class & bounding box regressor
Faster R-CNN
= Region Proposal Network + Fast R-CNN
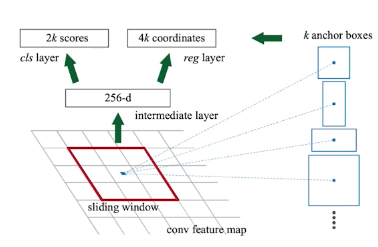
Region Proposal Network
이 박스안에 물체가 있을지 없을지 판단
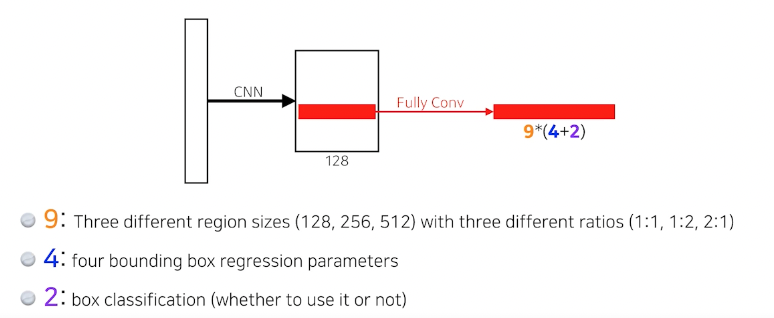
- Anchor boxes : 미리 box 사이즈, 템플릿을 정해놓음
YOLO
매우 빠른 object detection
-> multiple bounding boxes, class probabilities를 동시에 예측
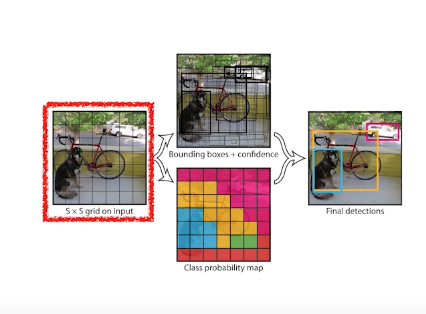 이미지가 들어오면 SxS의 grid로 나누고
grid에 해당하는 물체가 무엇인지 확인
이미지가 들어오면 SxS의 grid로 나누고
grid에 해당하는 물체가 무엇인지 확인
B개의 bounding box를 찾아주게 되고 실제로 쓸모 있는지 그와 동시에 bounding box가 어디 class인지도 확인
따라서 tensor는 $SS(B*5+C)$
SxS : grid의 cell의 숫자 B : bounding boxes with (x,y,w,h) 오프셋이랑 가로세로 길이, confidence C : number of class
댓글남기기