DL-8 Transformer
sequential model의 해결 문제
이를 해결하고자 transformer
Transformer
: first sequence transduction model based entirely on attention.
이미지 분류, detection, dall-e 등 다양하게 사용되고 있음
크게 인코더 디코더 형식으로 이루어져 있다
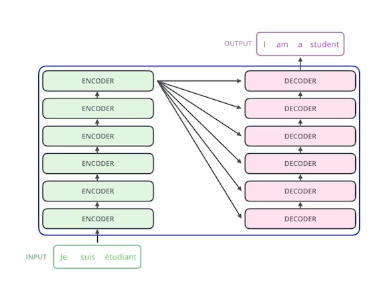 한번에 n개의 단어를 처리할 수 있는 인코더
한번에 n개의 단어를 처리할 수 있는 인코더
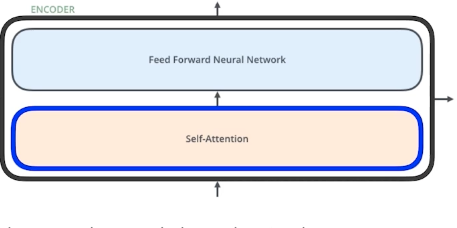
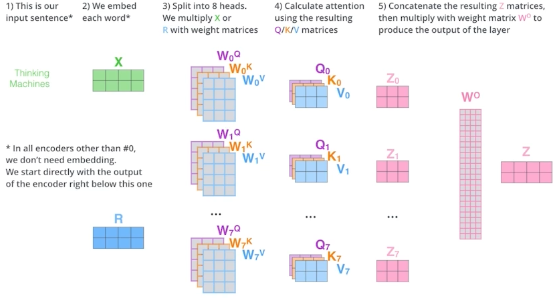
self-attention이 사실상 핵심이다 (인코더, 디코더에 다 들어감)
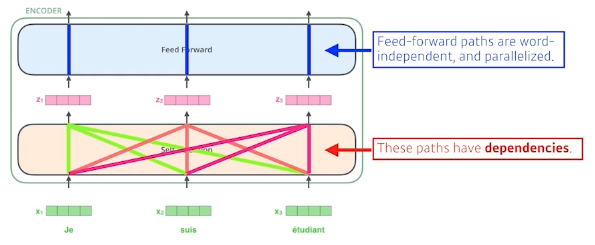 self attention에는 dependency가 있다
self attention에는 dependency가 있다
Self-attention
다른 단어들 과의 관계성을 가지게 알아서 학습됨 따라서 단어를 더 잘 이해하고 표현할 수 있게 됨
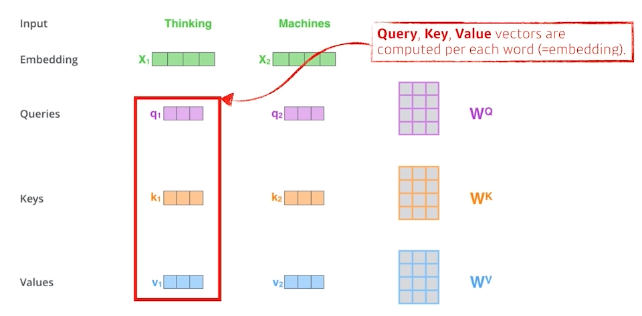 주어진 각각의 단어들을 벡터화 하여
각각의 벡터마다
주어진 각각의 단어들을 벡터화 하여
각각의 벡터마다
- Query
- Key
- Value
를 각각의 NN을 통해 생성함.
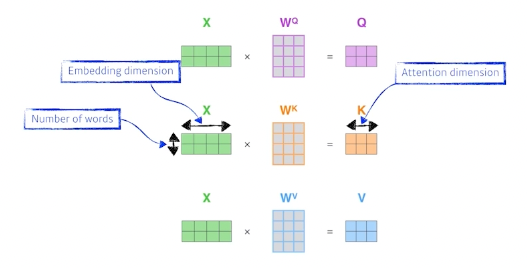
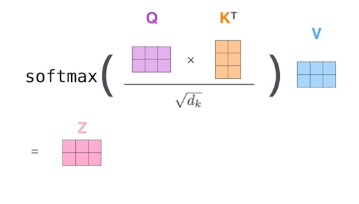
1) score 내가 encoding하고자 하는 vector의 query벡터와 자기 자신을 포함한 모든 key vector들을 내적하여 score 하나씩 구하여 다른 단어들과 interaction 점수를 구해본다,
2) normalization, softmax devide by $\sqrt{d_k}$ ($d_k$ = key vector의 dimension ) 이후 softmax를 통해 값을 구함.
-> attention weight 구함
3) Softmax * Value
4) Sum 마지막 인코딩 과정은 value vector들의 weigted sum으로 마무리
Positional Encoding
입력에 특정 값을 더해주는 bias 같은 역할
self attention은 order에 independent하다. 따라서 이를 보완하기 위한 장치.
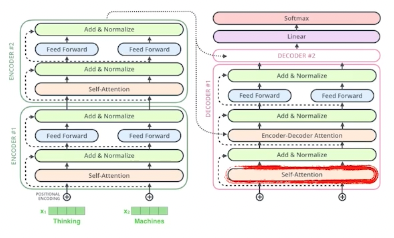
Decoder
encoder로 부터 key, value값을 받아서 attention계산
-
self attention 학습 시에는 making을 통해 이전 단어들에만 dependent하도록 함.
-
encoder-decoder attention 지금 decoder에 들어가는 단어들로 query 지정, 나머지는 encoder의 key, value 사용하여 계산
마지막 층은 단어들의 분포를 만들어서 샘플링하는 방식으로.
Examples
- Visual Transformer
- Dall-E
댓글남기기