RS10 - Bandit for Recommendation
0. Multi Armed Bandit(MAB)
: K개의 슬롯머신에서 얻을 수 있는 reward의 확률이 모두 다르다고 가정할 때,
수익을 최대화 하기 위해서는 어떤 policy에 의해 arm을 당겨야 하는가?
-
- 문제점
- 슬롯 머신의 reward 확률을 정확히 알 수 없다.
Exploration & Exploitation trade-off
- exploration(탐색) : 더 많은 정보를 얻기 위해 새로운 arm 선택
- exploitation(활용) : 기존의 경험 혹은 관측 값을 토대로 가장 좋은 arm을 선택
exploration 과 exploitation 둘의 비율을 적절하게 해야함
MAB formula
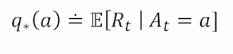

모든 action에 대한 $q_{*}(a)$ 를 정확히 알고 있다면 문제 해결
$q_{*}(a)$ 에 대한 시간 t 에서의 추정치 $Q_t(a)$ 를 최대한 정밀하게 구하는 것이 목표
추정 가치가 최대인 action을 선택하는 것 -> greedy action : explitation
greedy action 아닌 다른 선택 : exploration
1. MAB 기초
Greedy algorithm (simple average method)

매 time step 마다 reward가 수집됨에 따라 업데이트 됨
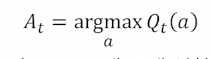
문제 : policy 가 처음 선택되는 action과 reward 에 크게 영향을 받음 (exploration 부족)
이를 해결하기 위한
Epsilon - Greedy Algorithm
일정한 확률에 의해 랜덤으로 슬롯머신을 선택하도록 함

ex) 동전을 던져 앞면이 나오면 greedy , 뒷면이 나오면 랜덤 선택, epsilon = 0.5
후반에 데이터가 싸여도 epsilon에 따라서 선택하기 때문에 후반부에는 손해일 수 있음
Upper Confidence Bound(UCB)
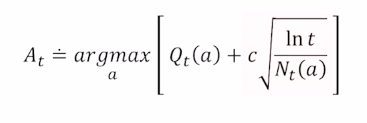

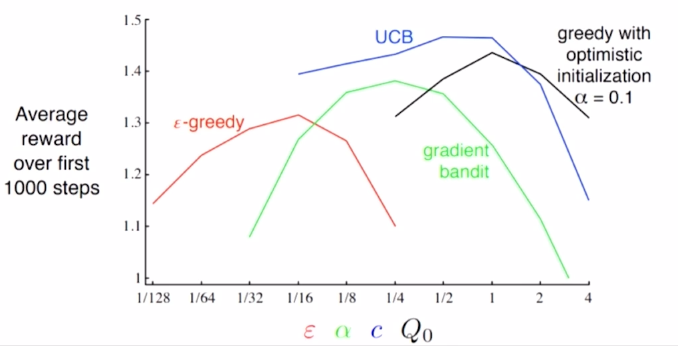
하이퍼파라미터 튜닝
추천시스템 예시
- 기존 추천
1) 유저에게 아이템 추천
2) 주어진 아이템과 유사한 아이템 추천
- Bandit 문제
클릭, 구매를 모델의 reward 로 가정
해당 reward를 최대화하는 방향으로 모델이 학습되고 추천을 수행함
-> 간단한 bandit으로도 온라인 지표 (CTR, CVR) 좋아짐!
- MAB 추천 시스템
-> 유저에게 아이템을 추천하는 방식을 policy로
-> 아이템 추천했을 때 사용자 클릭 여부 reward로 측정
-> 구현이 간단하고 이해가 쉬워 현업에 유용
- MAB 추천 예시
1) 유저 추천
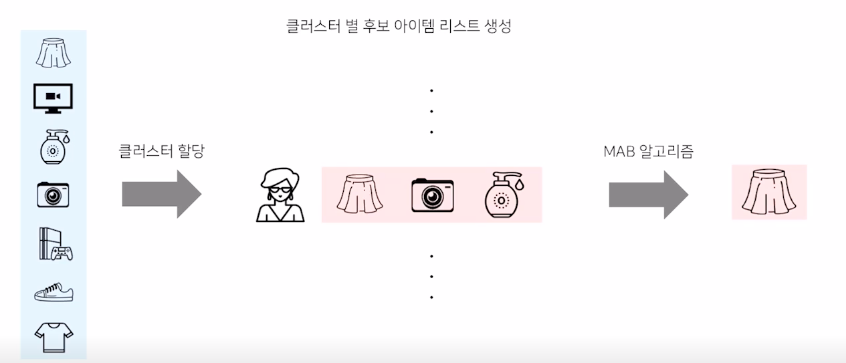
클러스터링을 통해 비슷한 유저끼리 그룹화한 뒤에 해당 그룹 내에서 Bandit 구축
-> Bandit 개수 = 유저 클러스터 개수 * 후보 아이템 개수
2) 유사 아이템 추천
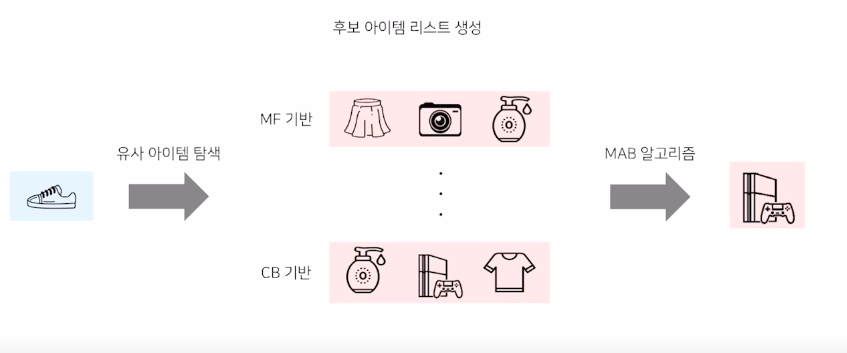
주어진 아이템과 유사한 후보 아이템 리스트를 생성하고 그 안에서 Bandit을 적용함
유사한 아이템 추출 방법 MF, Item2Vec 기반의 유저0아이템 기반 유사도 / Content-based 기반 유사도
-> Bandit 개수 = 아이템 개수 * 후보 아이템 개수
2. MAB 심화
Thompson Sampling
주어진 k개의 action에 해당하는 확률분포를 구하는 문제 ($Q_t(a)$ 가 베타 분포라는 확률 분포를 따른다고 가정)
- 베타 분포
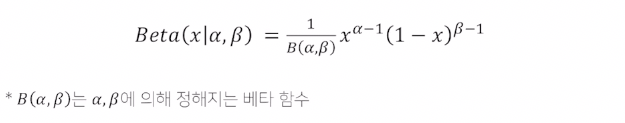
두개의 양의 변수로 표현할 수 있는 확률 분포이며 0~1 값을 가진다
- 수도 코드

LinUCB
- Contextual Bandit

- LinUCB
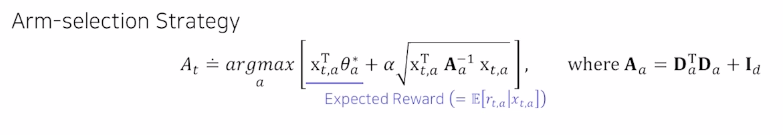

- 수도 코드

- 예시
Naver AiRS 추천 시스템
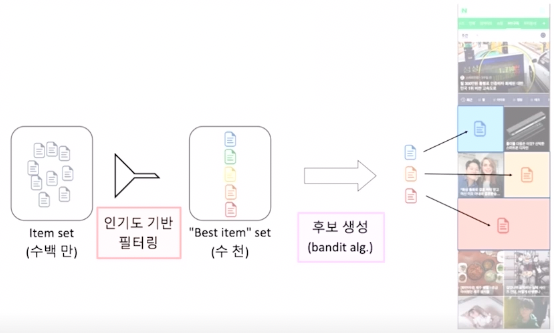
인기도 기반 필터링을 통해 exploration 대상을 축소한뒤
Contextual Bandit 을 통해 유저의 취향 탐색 및 활용
댓글남기기