RS2- 추천시스템 basic
전체 개요

Association Rule Analysis
= Association Rule Mining = 연관 (규칙) 분석 = 장바구니 분석, 서열 분석
상품의 구매, 조회 등 하나의 연속된 거래들 사이의 규칙을 발견하기 위해 적용
-> 하나의 상품이 등장 했을 때 같이 등장하는 규칙 찾기 (인과관계는 아님)
-
규칙 : If (condition) Then (result) {condition} -> {result} 형식으로 표현
-
연관규칙 : If (antecedent) Then (consequent) 사건이 발생했을 때 함께 빈번하게 발생하는 또 다른 사건의 규칙
-
itemset : antecedent 와 consequent를 구성하는 상품들의 집합(1개 이상) (antecedent와 consequent는 서로소를 만족해야 함)
-
- support count($\sigma$)
- 전체 transaction data 에서 itemset 등장 횟수
-
- support
- itemset이 전체 transaction data에서 등장하는 비율
-
- frequent itemset
- minimum support 값 이상의 모든 itemset
연관 규칙의 척도

1) support
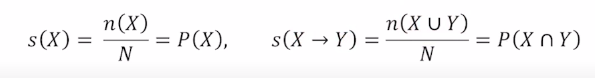 *support x값은 항상 support(x-> y) 보다 크거나 같다
*support x값은 항상 support(x-> y) 보다 크거나 같다
2) confidence :조건부 확률
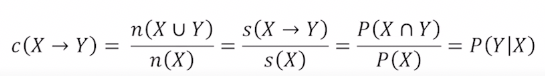
3) lift : (X가 포함된 transaction 가운데 Y가 등장할 확률 ) / (Y가 등장할 확률)
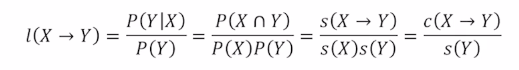
- lift = 1 : x,y 독립
- lift > 1 : 양의 상관관계
- lift < 1 : 음의 상관관계
사용 방법
1) minimum support, minumum confidence로 의미없는 rule screen out 2) lift 값으로 내림차순 정렬하여 rule 평가
Mining Association Rules
: 연관 규칙의 탐색 (minimum support, confidence 만족하는)
-
- Brute-force approach
- 가능한 모든 연관 규칙 나열, support와 confidence 계산해서 minimum 값에 맞는 값만 남기고 모두 pruning

사실상 계산적으로 불가능
효율적인 Association rule mining 의 두 스텝
1) Frequent itemset generation : minimum support 이상의 모든 itemset 생성
(1) 가능한 후보 itemset 개수(M) 줄임
-Apriori 알고리즘
(2) 탐색하는 transaction 숫자(N) 줄임
-DHP(direct hashing & pruning) 알고리즘
(3) 탐색 횟수를(NM) 줄인다
-FP-Growth 알고리즘
2) Rule generation : minimum confidence 이상의 association rule 생성
TF-IDF 활용 컨텐츠 기반 추천
TF-IDF : 텍스트 데이터를 다루는 가장 기본적인 방법
텍스트 데이터를 활용한 컨텐츠 기반 추천
컨텐츠 기반 추천(content-based recommendation) : 유저 x가 과거에 선호한 아이템과 비슷한 아이템을 유저 x에게 추천
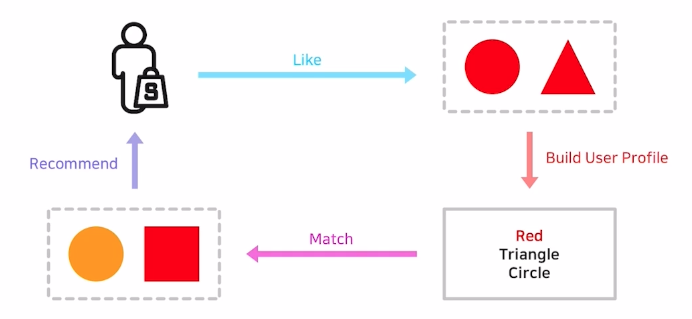
- 장점
- 다른 유저의 데이터가 필요 없음
- 새로운, 인기도가 낮은 아이템 추천 가능
- 추천 아이템에 대한 설명이 가능
- 단점
- 아이템의 적합한 피쳐를 찾는 것이 어려움
- 한 분야/장르의 추천 결과만 계속 나올 수 있음 (overspecialization)
- 다른 유저의 데이터를 활용할 수 없음
Item Profile
아이템의 속성을 어떻게 표현? -> Vector 형태!
- TF-IDF for Text feature (Term Frequency - Inverse Document Frequency)
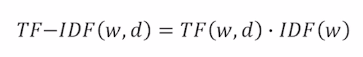
TF : 단어 w 가 문서 d 에 등장하는 횟수

IDF : 전체 문서 가운데 단어 w가 등장한 비율의 역수

(smoothing 을 위해 log 사용함)
User Profile 기반 추천하기
각 유저의 item list 에 있는 item vector를 통합하면 user profile이 됨
통합 방법 1) Simple : 선호 Item vector들의 평균값 2) Variant : 아이템 선호도로 normalize한 평균값
ex)
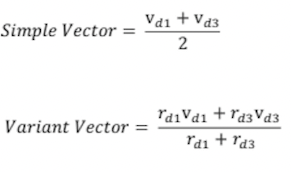
Cosine similarity
두 벡터 X, Y에 대하여
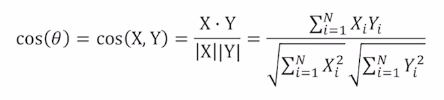
직관적으로 두 벡터의 방향 유사도
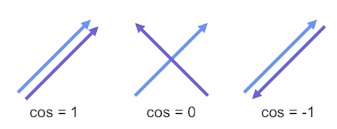
유저와 아이템 사이의 거리 계산하기
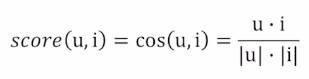
score 높은 아이템 부터 유저에게 추천
Rating 예측하기
유저($u$)가
선호하는 아이템($I = {i_1, …, i_N}$)의
item vector($V = {v_1,…,v_N}$)를 활용하여
기존 평점 ($r_{u,i}$)를 이용하여
새로운 평점 예측하기

댓글남기기