RS5 - Item2Vec and ANN
Item2Vec
ㄴ word2vec 을 추천시스템에 적용한 것
Word2Vec
-
임베딩 : 주어진 데이터를 낮은 차원의 vector로 표현 1) sparse representation :아이템 전체 가짓수와 차원의 수가 동일 2) dense representation :아이템 전체 가짓수보다 훨씬 작은 차원으로 표현
-
워드 임베딩 : 단어를 벡터로 표현하는 방법
-> 단어간 의미적인 유사도 구할 수 있음
-> 임베딩 표현위한 학습 모델이 필요함(여기서는 Matrix Factorization)
- 학습 방법 1) CBOW(Continuous Bag of words)
주변 단어로 센터의 단어 예측하는 방법
앞뒤로 몇개 쓸껀지 정해야함
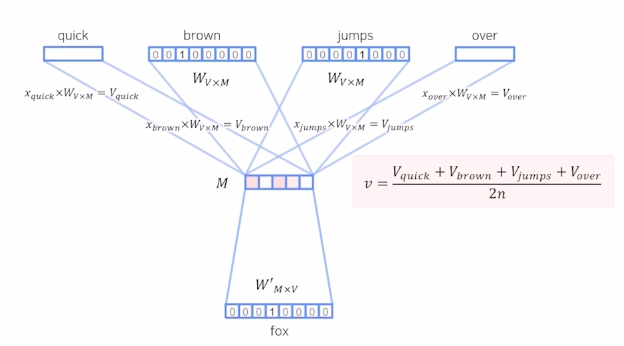
학습 파라미터 $W_{VM}, W’_{VM}$
2) Skip-Gram
CBOW의 입력층과 출력층이 반대로 구성된 모델
가운데 단어로 주변 단어 이끌어 내는 것
CBOW보다 일반적으로 성능이 좋음
3) Skip-Gram with Negative Sampling (SGNS)
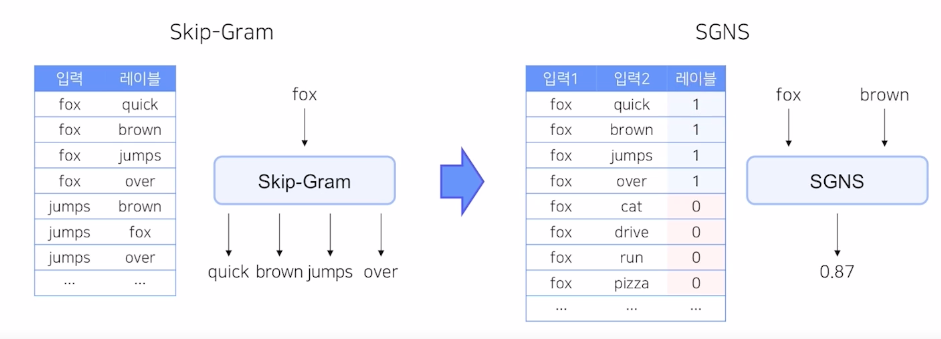
binary class classification으로 방식을 바꿈
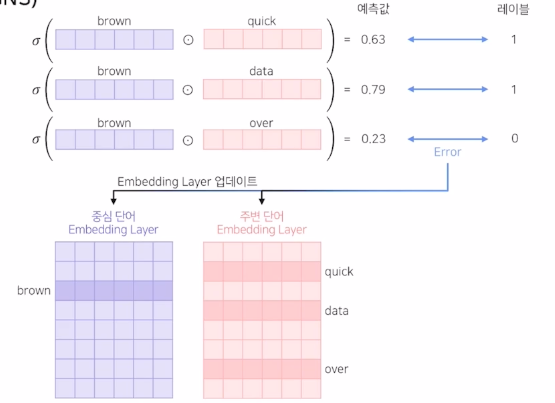
1) 중심 단어를 기준으로 주변 단어들과의 내적의 sigmoid를 예측값으로 하여 0,1 분류
2) backpropagation을 통해 각 임베딩이 업데이트 되면서 모델이 수렴함
3) 최종 생성된 워드 임베딩 2개를 하나만 사용하거나 평균을 사용
Item2Vec
- (neural item embedding for collaborative filtering)
-
추천 아이템을 Word2Vec을 사용하여 임베딩
SGNS 기반으로 아이템을 벡터화 해보자
-
- 데이터
- 유저 혹은 세션 별 소비한 아이템 집합을 생성
공간적 정보를 무시하므로 동일한 집합 내 아이템 쌍들은 모두 SGNS의 positive sample이 됨
ex) 유저가 item a,b,c를 소비했다고 하면

- Item2Vec 활용 사례

ANN(approximate nearest neighbor)
-
NN (Nearest Neighbor) Vector space model에서 내가 원하는 query vector와 가장 유사한 vector를 찾는 알고리즘
-
Brute Force KNN 정확도를 조금 포기하고 아주 빠른 속도로 주어진 vector의 근접 이웃을 찾아보자!
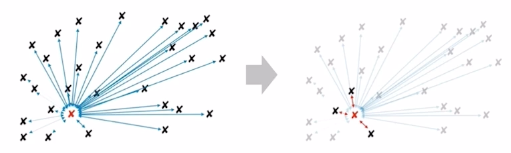

ANNOY
: spotify 에서 개발한 tree-based ANN 기법
벡터들을 여러개의 subset으로 나누어 tree 형태의 자료구조로 구성하고 이를 활용하여 탐색함
-> binary tree형식
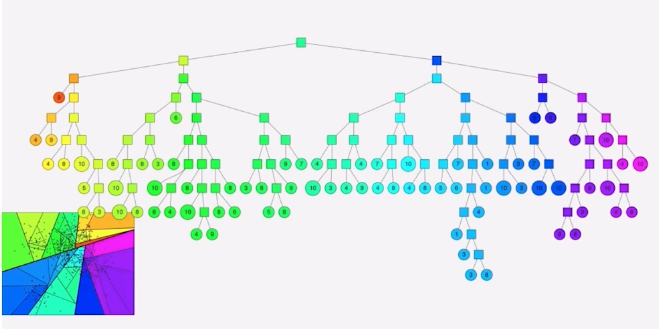
log(n)시간만에 관련 subspace를 찾고 이 안에서 찾을 수 있음
- 문제점 가장 근접한 점이 tree의 다른 node에 있는 경우 해당 점은 후보 subset에 포함못 함
-> 해결 방안 1) priority queue를 사용하여 가까운 다른 node를 탐색 2) binary tree를 여러 개 생성하여 병렬적으로 탐색
-
parameter 1) number_of_trees : 생성 binary tree 개수 2) search_k : NN 구할 때 탐색하는 node 개수
-
특징 1) ANN 기법에 비해 간단하고 가벼움 (GPU연산 지원 x ) 2) 검색할 이웃 개수를 알고리즘이 보장함 3) parameter를 통한 speed/ accuracy trade-off 4) 기존 생성된 binary tree에 새로운 데이터를 추가할 수 없음
기타 ANN 기법
Heirarchical Navigable Small world graphs (HNSW)
: 벡터를 그래프의 Node로 표현, 인접 벡터를 edge로 연결
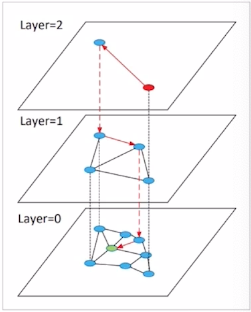
- 작동 방식 1) 최상위 layer에서 임의의 노드에서 시작 2) 현재 layer에서 타겟과 가장 가까운 노드로 이동 3) 하위 layer로 이동 4) 타겟 노드 도착 할 때 까지 2),3) 반복 5) 2)~4) 진행하며 방문한 노드들만 후보로 하여 NN을 탐색
Inverted File Index (IVF)
1) 주어진 vector 를 clustering을 통해 n개의 cluster로 나누어 저장 2) vector의 index 를 cluster별 inverted list로 저장
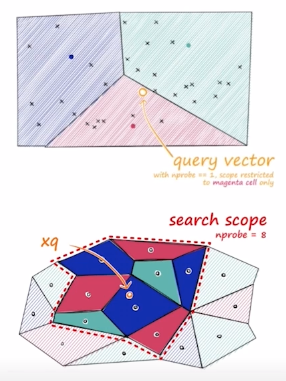
탐색 cluster 늘릴 수록 accuracy 증가/ speed 감소
Product Quantization - Compression
1) 기존 벡터를 n개의 sub-vector로 나눔 2) 각 sub-vector 군에 대해 k-means clustering을 통해 centroid를 구함 3) 기존의 모든 vector를 n개의 centroid로 압축해서 표현
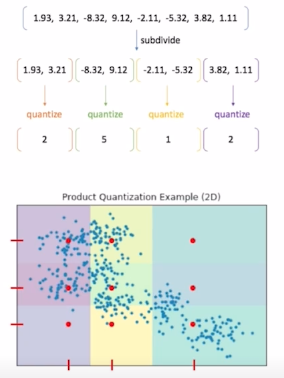
-> 두 vector의 유사도 연산이 거의 요구되지 않음 (O(1)) -> PQ와 IVF를 동시에 사용해서 빠르고 효율적인 ANN 수행 가능
댓글남기기