RS8 - Context-aware Recommendation
0. Context-aware Recommendation
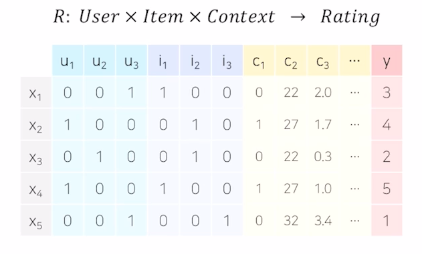
컨텍스트 기반 추천 시스템
->유저-아이템 상호작용 + 맥락적 정보(context)
Click-Through Rate Prediction
CTR 예측 : 유저가 주어진 아이템을 클릭할 확률 (주로 광고에서 사용)
-> sigmoid 함수로 마지막에 처리
유저 Id 존재하지 않아도 다른 유저, context 정보로 처리하기도 함
- 이진 분류 문제 - Logistic Regression
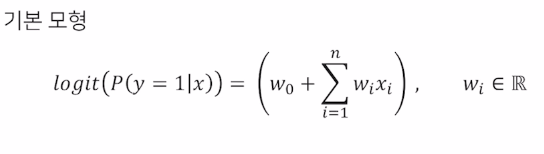
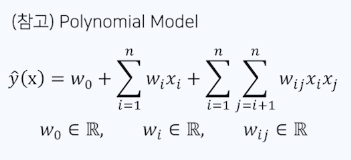
Polynomial Model

- 사용 데이터
Dense Feature : 비교적 공간 작은 벡터
ex) 평점, 기온, 시간
Sparse Feature : 비교적 공간 넓은 벡터
ex) 요일, 분류, 키워드, id
One hot encoding을 하면 파라미터가 너무 많아질 수 있고, overfitting, underfitting 일어날 수 있으므로
‘Feature Embedding’을 한 이후에 이 피쳐를 가지고 예측을 하기도 함
(자연어 처리에 사용되는 처리 기법, Item2Vec,BERT 등 사용됨)
1. FM(Factorization Machine)
SVM 과 Factorization model 의 장점을 결합함
SVM : 비선형 데이터셋에 대해 좋은 성능
MF : CF환경에서 좋은 성능 / 특별한 환경 혹은 데이터 에서만 적용 가능
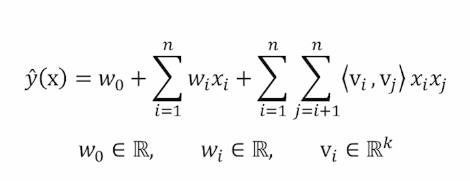
$w_0$ : global bias
$w_i$ : 각 변수에 대응되는 1차 파라미터
3번째 항 : Factorization term
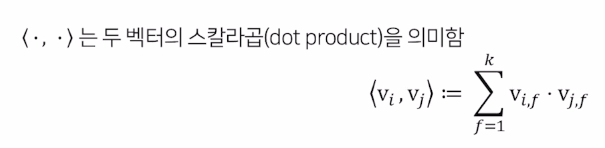
앞에 두항은 Logistic regression,
세번째항은 polynomial 과 비슷하지만 $v_i , v_j$ 로 나뉘어 일반화하여 나타냄
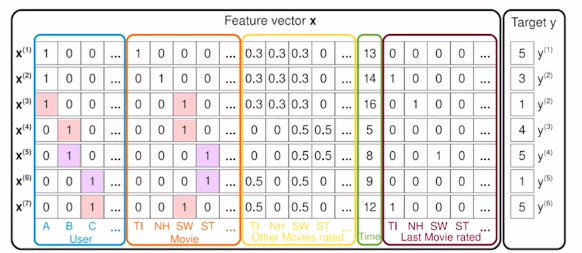
Sparse 데이터셋 예측하기
ex) 유저의 영화에 대한 평점 데이터

-> high sparsity data
유저 A의 ST에 대한 평점 예측
장점
- vs SVM sparse한 데이터에 대해 높은 예측 성능
선형복잡도(O(kn)) -> 수십억개 학습 데이터에도 빠른 학습
- vs Matrix Facotization 유저, 아이템 id 이외에 다른 부가 정보들을 피쳐로 사용
2. FFM(Field-aware Factorization Machine)
PITF 모델에서 아이디어를 얻어 FM을 변형, sparse 데이터의 CTR 예측에서 더 높은 성능을 보임.
- PITF : (Pariwise Interaction Tensor Factorization) user, item, tag 3개의 필드 클릭율 예측 위해 (user, item), (item, tag), (user, tag)서로에 대한 서로 다른 latent factor를 정의하여 구함
-> 이를 일반화하여 여러 개의 필드에 대해서 latent factor를 정의한 것이 FFM
- FFM 입력변수를 Field로 나누어, 필드별로 서로 다른 latent factor를 가지도록 factorize 함
Field : 모델 설계시 함께 정의, 같은 의미의 변수 집합으로 설정함
(보통 피쳐의 개수만큼 필드를 정의함)
공식 :

Factorization term이 바뀜
- FM vs FFM
ex) feature 세 개 (Publisher, Advertiser, Gender 일 때)
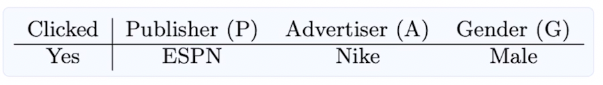

- FFM 필드 구성
1) Categorical Feature

2) Numerical Feature


3. Gradient Boosting Machine(GBM)
CTR 예측을 통해 personalized 추천 시스템 만들 수 있음.
-
- Boosting
- ensemble의 일종
decision tree 로 된 weak learner 들을 연속적으로 학습하여 결합하는 방식
ex) AdaBoost, GBM, XGBoost, LightGBM, CatBoost
-
- Gradient Boosting
- gradient descent 를 사용하여 loss function이 줄어드는 방향(negative gradient)으로 weak learner들을 반복적으로 결합함
ex) XGBoost, LightGBM, CatBoost
수도 코드

이전 단계의 weak learner 까지의 residual을 계산하여, 다음 weak learner를 학습함.
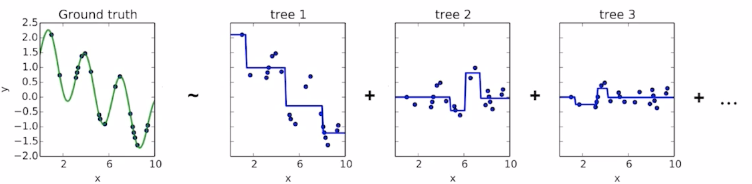
회귀 문제에서는 예측값으로 residual을 그대로 사용하고, 분류 문제에서는 log(odds) 값을 사용함
- 장단점 장점 : random forest 보단 남
단점: 1) 학습속도 느림 2) overfitting
댓글남기기