RS9 - DeepCTR
0. CTR prediction with deep learning
CTR 예측 1) highly sparse & super high-dimensional features 2) higly non-linear association between the features
1. Wide & Deep
- 해결해야할 두 과제 :
1) Memorization : 빈번히 등장하는 아이템 혹은 특성 관계를 과거 데이터로 부터 학습 (암기) 2) Generalization : 드물게 발생, 발생한적 없는 아이템/특성 조합을 기존 관계로부터 발견 (일반화)

구조
- The Wide Component
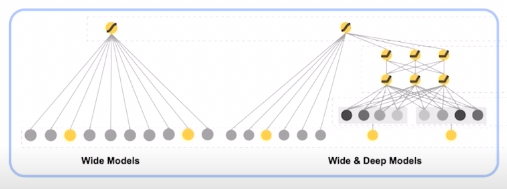
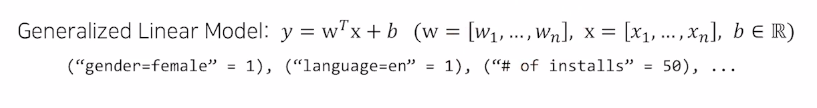
이렇게만 하면 서로다른 변수(x) 끼리 정보 알 수 없음

- The Deep Component
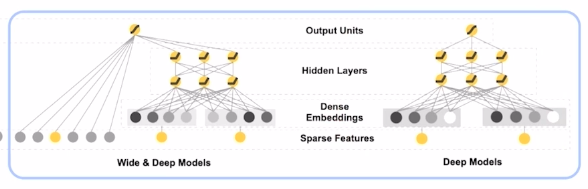
ReLu 사용, feed-forward 3층으로
- 전체 구조
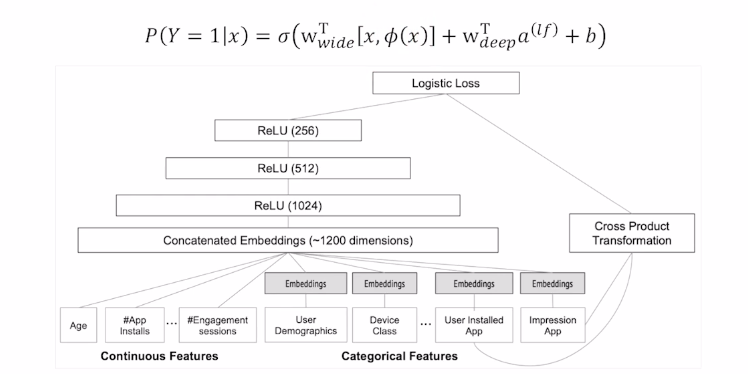
x : 변수 pi(x) : cross product transformation
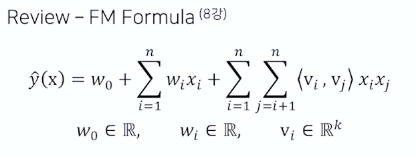
2. DeepFM
FM 모델에 Deep component 추가
- 등장 배경
implicit feature interaction 학습이 중요함
기존 모델들은 low- 나 high-order interaction 중 어느 한 쪽에만 강함
wide&deep 은 이 둘을 통합 했으나, wide 에 feature engineering(cross-product transformation) 이 필요하다는 단점이 있음
=> 
구조
1) FM Component
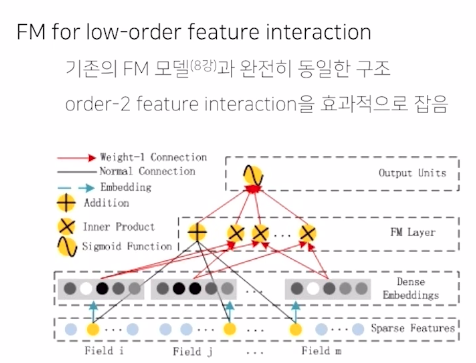
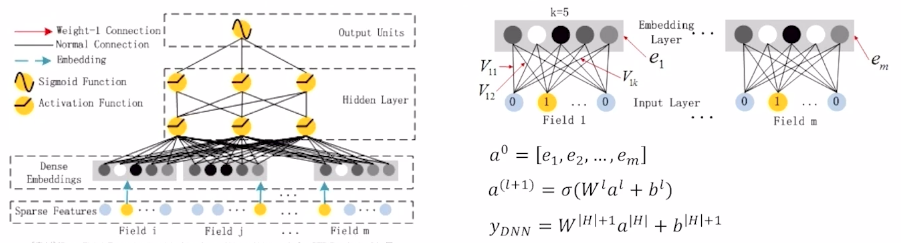
2) Deep Component
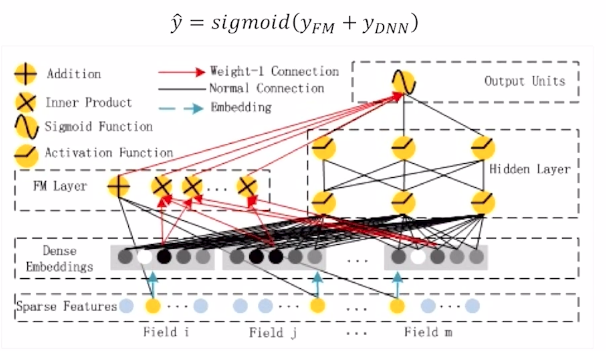
- 전체 구조
비교
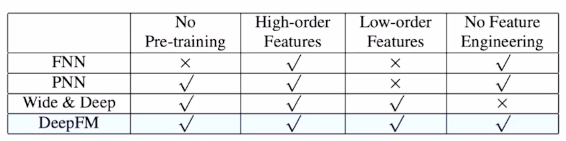
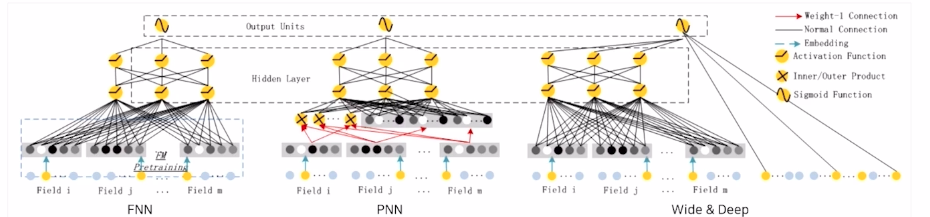
모델 성능 : DeepFM 이 그 전것들 보다 좋다
3. Deep Interest Network (DIN)
- 등장 배경 다양한 feature를 모델에 사용하고자
기존의 Embedding & MLP 패러다임 탈출
-> 사용자가 기존에 소비한 아이템의 리스트를 user behavior feature로 만들어,
예측 대상 아이템과 이미 소비한 아이템 사이의 관련성을 학습
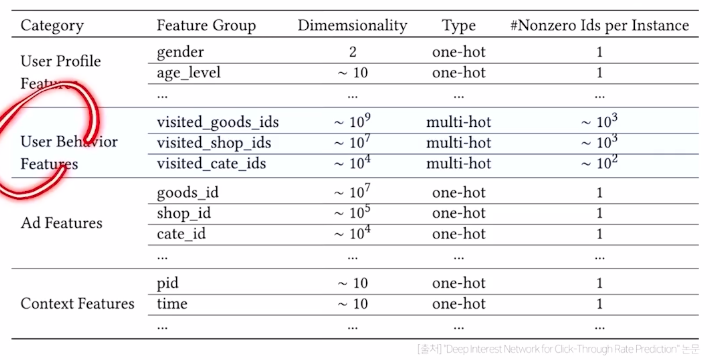
multi-hot encoding의 방식으로 어떤 것을 샀는지
구조
1) Embedding layer 2) Local Activation layer (핵심 -> user behavior feature 적용) 3) Fully- connected layer
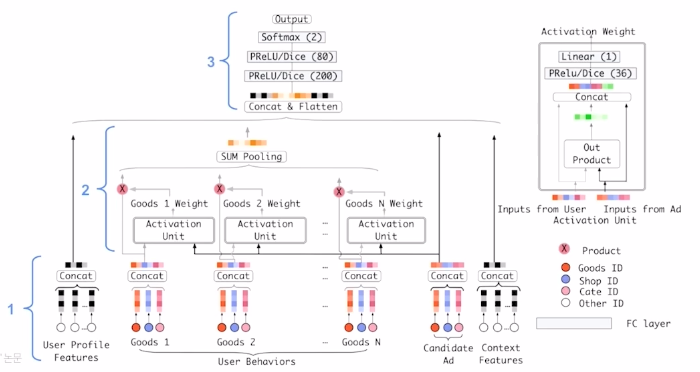
- Local activation 후보군이 되는 광고를 기존에 본 광고들의 연관성으로 계산하여 Weight로 표현
(-> transformer 의 attention 과 유사)
-
- Weighted Sum Pooling
- 여러 개의 표현 벡터를 가중 합한 값을 출력으로 사용
*추가설명 - Local Activation Layer
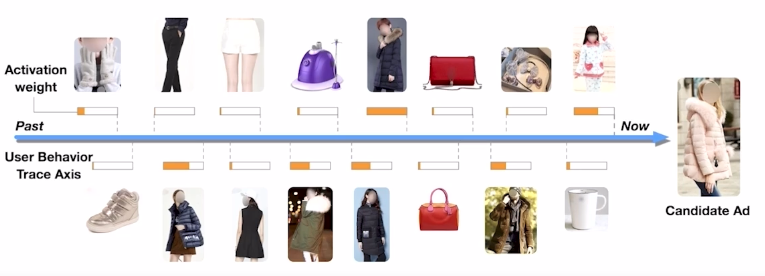
4. Behavior Sequence Transformer (BST)
Transformer를 사용한 CTR 예측
구조
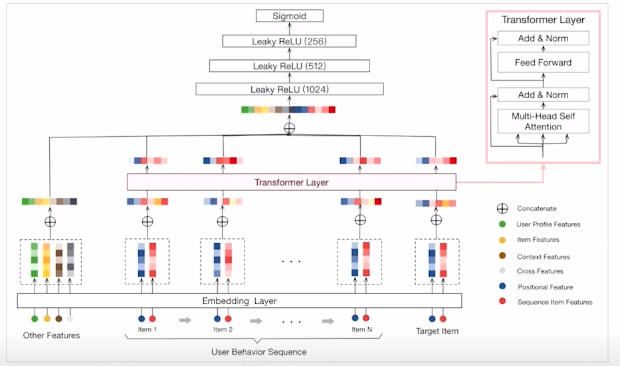
입력 부분에 user behavior sequence를 그대로 넣어 줌
other feature 에는 user feature, context feature 등 sequence 아닌거 넣어주고 embedding 한뒤 바로 적용
Transformer의 encoder 부분만 사용
수식:



비교
- vs DIN local activation layer -> transformer layer
user behavior feature -> user behavior sequence
- vs Transformer dropout 과 LeakyReLU 추가
레이어 1~4개 사용 (best는 1개 일 때)
Custom Positional encoding
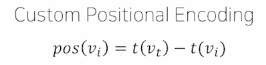
모델 성능
transformer 짱이다.
2개 이상 transformer 블록 쌓을 때 오히려 성능이 감소 (NLP 보다 CTR의 sequence 가 덜 복잡한 것으로 보임)
댓글남기기